目录
介绍
对于工程师来说,排查不一样的问题,往往会有不一样的难点。有的问题难在重现,但只要能重现一次,根据场景和借助工具分析,加上对业务和代码了解,问题就可以迎刃而解。今天,将和大家分享一个在高并发场景下的java应用假死问题的分析案例。
这是个在高并发场景下才出现java内存泄露,导致应用假死的问题,下面将一步步分析和定位到具体代码的排查过程,希望对新手和同行有点参考价值的,所以就记录了一下
现象
首先我简单解释问题现象,我们的一个产品,有17万用户,每天活跃用户在7-8万左右。后台Java应用从上线以来,此应用还未出现过假死的情况,最近,因紧急处理其他问题,在高峰期没有灰度的情况下将后台三个java应用重启了,但是,其中有一个应用运行2小时后,就出现了假死情况,用灰度方式重启了此应用,其他2个应用一直运行到第二天早上9点左右出现了问题,且隔了4个小时,最后一个应用也出现了响应超时,应用假死情况。我们采取灰度的方式重启了应用,就再也没有出现了假死的情况了。
问题分析和定位
我们在平常工作中,像这种因CPU飙高、内存泄露或频繁FullGC等情况,会将现场保护下来,使用JVM工具分析,比如CPU飙高用,我们使用李鼎大牛写的show-busy-java-threads.sh分析,可直接找到代码段;内存泄露,就使用jmap将内存快照下来用mat分析。但是这次,因其他紧急事情,也不太重视的情况下,前两次加上现场没有保护下来,找到问题困难重重。
现场无法保护
第一次发生假死,是在重启后2小时出现了,当时因有大量的用户在线使用系统,加上有其他紧急的事情需处理,当时只是让运维同学用灰度方式重启了应用,保障用户可以在线使用,没太放在心上,所以现场没有保护下来分析。第二次发生假死情况在第二天早上9点,因人在上班路上,没接触到现场,为了保障用户正常使用,也让运维同学重启了应用,现场也没保存下来。加上2个应用都出现了假死情况,我们意识,这是个不定时的炸弹,不解决和不找到问题所在,随时会出现假死情况,影响客户体验和使用,我们非常重视这个问题了。像这类问题,如果想找到原因,只能等下一次假死情况出现了,将现场保护起来,进行分析。
问题状况和思考
还在上班的路上,一直在思考下面的两个问题:1. 为什么应用会假死;2. 发生假死之前,应用一直是正常运行,从上线以来,还从未出现过假死情况,为什么这次会出现假死
应用假死可能的原因:
1.) tomcat的处理线程已满,出现了饥饿情况,某些线程长时间得不到需要的资源而不能执行的现象。但仔细思考,早上这个上班点发生,人比较少,除非被攻击了,结合之前未出现情况,判断这个原因几率比较小
2.) 硬件或其他机器问题。 这个可以排除,三个应用部署不同的机器上,有问题不可能一起出现机器硬件问题
3.) 因内存泄露问题,导致jvm一直做FullGC。 很可能跟这个有关系,但是仔细思考,这次发生假死之前,从未出现过这样的情况,根据以往的经验,我们推测可能的原因: 可能1) 与前两天发了一次版本有关系(如:用户关闭窗口后需调用退出接口需清理会话信息)。 可能2) 改了其他的服务器的参数,比如jvm的启动参数改变
4.) 其他原因……
整理后的思路是大概是这样的,先找到假死的直接原因,根据假死的直接原因顺藤摸瓜找到原因所在。
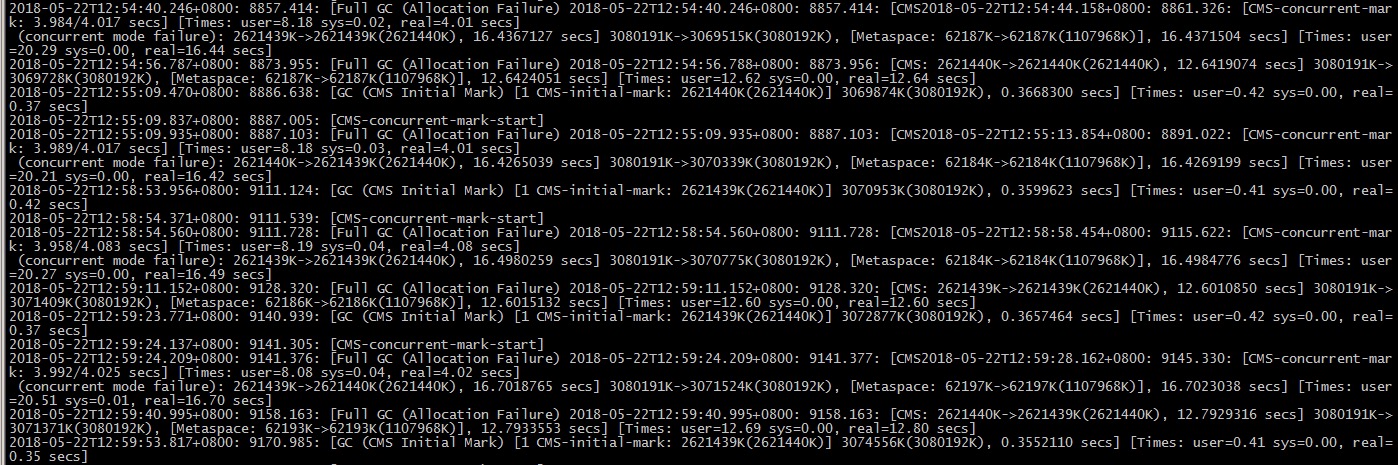
上班后,查看了GC的日志,如下图,果不其然,发现我们的应用频繁FullGC,应用一直STW,就知道是因为内存泄露导致应用假死的直接原因所在了。为什么会发现内存泄露呢?因为这次发生之前从未发生过,这次偏偏发生了,啥原因呢? 因为我们前2次没有将现场的内存快照下来,无法找到代码层面的问题。为了找到问题代码,所以只能等下次出现问题,将内存快照下来,使用mat工具分析,找到导致内存泄露问题的代码。
假死原因分析
果不其然,在中午接近13点左右,刚点餐吃饭,收到客服反馈的问题跟之前两次一样,我推测,一定是第三个应用也出现了假死情况,直接回公司,将流量切换到灰度机器上,现场保护了下来。
先用jstat -gc pid 3000 查看了进程的GC情况(未截图保存下来),发现FGC这列值很大有100多次,FGCT时间长达300秒,而且数值还一直在涨,据此JVM频繁在做FullGC,Stop the world,出现了应用假死情况。
接着,用jmap -dump:format=b,file=32443jvm.bin pid命令将内存快照保存下来,下载到本地,使用mat工具分析如下图。有大量系统自动命名的线程达65个,且每个线程占用了内存40-44M,按照42M平均计算,65个线程所需内存达到2.73G,所以为什么一直FullGC了,导致应用假死了。
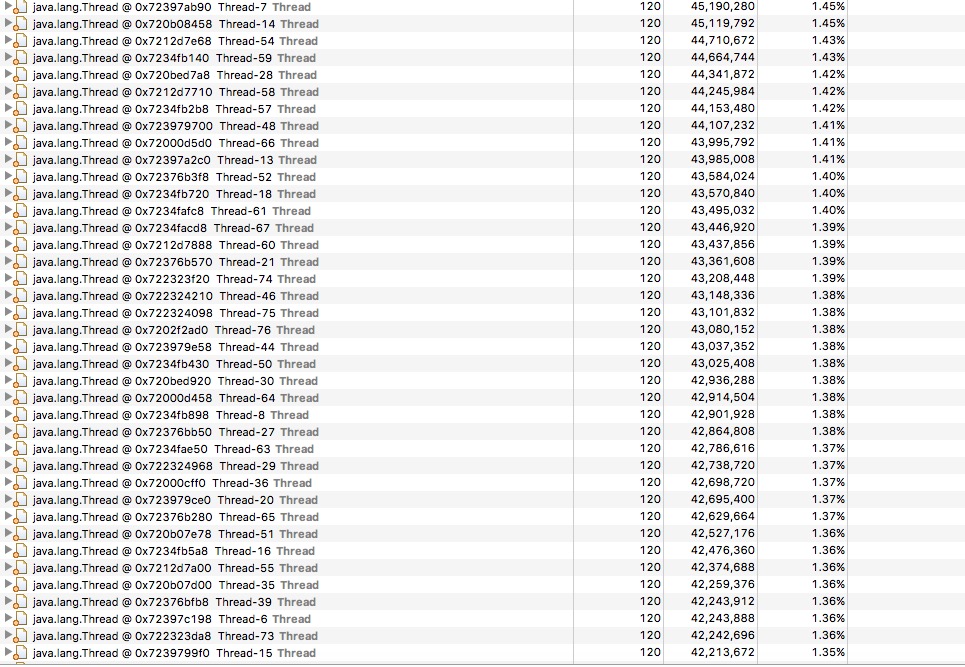
好吧,到这里,通过代码了解和走读,这么多的线程应该可以找到相关问题代码,但是叫上研发和我一起分析相关的代码,对于用到的多线程而且未命名的代码都走读了一遍,对照一看,业务代码上真未发现启动了这类线程的。恩… 没有了线索,是什么代码启动这么多线程,为什么一下子启动这么多线程,而且占用的内存这么大呢? 又陷入了思索…
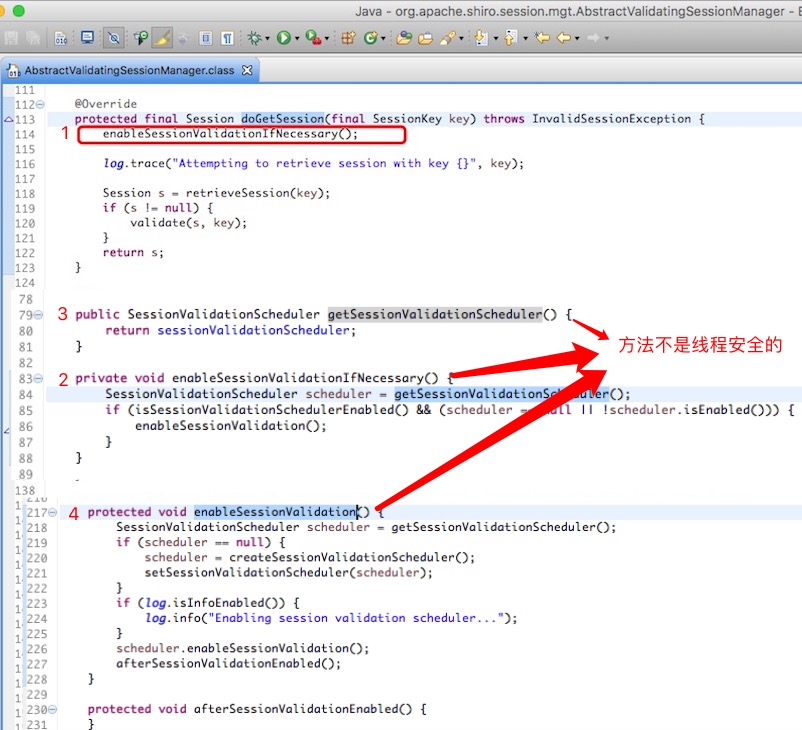
思考了一阵,决定从内存快照中在找找线索,网上找了些资料,参照网上他人分析内存快照经验看,采用Java Basics - Thread Details方式随机打开这65个线程的线程堆栈,都指向org.apache.shiro.session.mgt.AbstractValidatingSessionManager.validateSessions()方法,是org.apache.shiro.session.mgt.ExecutorServiceSessionValidationScheduler启动了这个线程,如下图。

在下载shiro框架的源代码和我们配置信息,查看发现shiro在接受到第一个请求的时,org.apache.shiro.session.mgt.AbstractValidatingSessionManager类会启动一个会话定时2个小时清理过期会话的未命名线程,重要的是这个启动这个线程的相关方法都是不是线程安全的,如下图,在高并发场景下,同一个时间点同时接收到大量请求,会开启多个这样的线程,与我们内存快照的一对比,嗯~~~~ 就是它了。
接着,复盘下问题情况,昨天应用重启,是在流量没有切走的时候重启的,在同一个时间点,高并发流量调用非线程安全的方法,开启了大量的清理会话的线程(65个会话清理线程),当用户会话信息过多,每个线程从远程Redis存储获取所有的会话信息到本地进行判断,需开辟了一个42M左右的内存用于此会话信息,65个线程所需内存达到2.73G,短时间内撑爆了内存,导致应用假死。另外,昨天第一个应用发生假死后,在没有流量情况下重启了应用,进行了灰度发布,没有启动大量的清理会话线程,所以没有出现假死的情况
修复问题
继承了shiro框架的一个类DefaultWebSessionManager,实现了spring的InitializingBean接口,在spring实例化完这个类后,启动定时清理过期会话线程,保证只启动一个线程,这样保证了在高并发流量下不会启动多个清理过期会话线程。修改好代码后,发布到线上,结合日志和运行情况看,问题解决。
总结
回顾这个问题的处理过程,这个问题本来并不算是什么疑难杂症,难点在于在一些特定的场景才会出现问题,比如这次是开源框架shiro,接收第一个请求时启动会话过期线程,在一般情况下不会出现问题,但是高并发同时请求下会启动多个会话过期清理线程,导致内存泄露问题。但是,只要问题能重现,没有什么不能解决的问题。
- 最近更新的三个文章
- 28 Jan 2019 » CMS之promotion failed&concurrent mode failure
- 17 Jan 2017 » docker中定制openresty笔记
- 16 Jun 2015 » 并行SSH运维工具pssh